
The Predictable Scaling of Value-Based Deep Reinforcement Learning
A New Frontier in AI?

One of the challenges has been understanding how machine learning models scale with increasing computational resources and data. This question is pertinent in the realm of reinforcement learning (RL), where algorithms learn to make decisions by interacting with an environment, often requiring massive amounts of data and computational power. A recent paper titled "Value-Based Deep RL Scales Predictably" by Oleh Rybkin and colleagues from the University of California, Berkeley, and Carnegie Mellon University, focuses new light on this issue. The study reveals that value-based deep RL methods, which have long been considered unpredictable at scale, actually exhibit predictable scaling behavior.
The Scaling Challenge in Machine Learning
In recent years, the success of machine learning has been largely driven by the ability to scale models and datasets. From language models like GPT-4 to image generators like DALL-E, the trend has been clear: bigger models trained on more data tend to perform better. However, scaling is not just about throwing more resources at a problem; it’s about doing so efficiently and predictably. Researchers want to know how much data and compute are needed to achieve a certain level of performance, and they want to be able to predict this without running prohibitively expensive large-scale experiments.
This predictability is especially important in reinforcement learning, where the cost of data collection can be extremely high. Unlike supervised learning, where data is often static and pre-collected, RL algorithms must interact with an environment to gather data, which can be time-consuming and expensive. Moreover, RL algorithms are notoriously sensitive to hyperparameters, making it difficult to predict how they will perform when scaled up.
The Promise of Value-Based RL
The paper focuses on value-based RL methods, which are a class of algorithms that learn to estimate the value of different actions in a given state. These methods, which include popular algorithms like Soft Actor-Critic (SAC) and Q-learning, are known for their efficiency in environments with dense rewards. Unlike policy gradient methods, which directly optimize the policy, value-based methods learn a value function that can be used to evaluate the quality of different actions. This makes them particularly well-suited for tasks where environment interaction is costly, as they can learn from arbitrary data without requiring extensive sampling or search.
However, despite their potential, value-based RL methods have been plagued by a reputation for unpredictability. Conventional wisdom suggests that these methods suffer from pathological behaviors when scaled up, such as overfitting or plasticity loss, where the algorithm becomes less capable of adapting to new data as training progresses. This has led many researchers to focus on other approaches, such as policy gradient methods or model-based RL, which are perceived as more stable at scale.
Breaking the Myth: Predictable Scaling in Value-Based RL
The new study challenges this conventional wisdom by demonstrating that value-based RL methods can, in fact, scale predictably. The key insight lies in understanding the relationship between three critical hyperparameters: batch size (B), learning rate (η), and the updates-to-data (UTD) ratio (σ). The UTD ratio, which measures how many times the algorithm updates its parameters per unit of data collected, plays a central role in determining the algorithm’s performance.
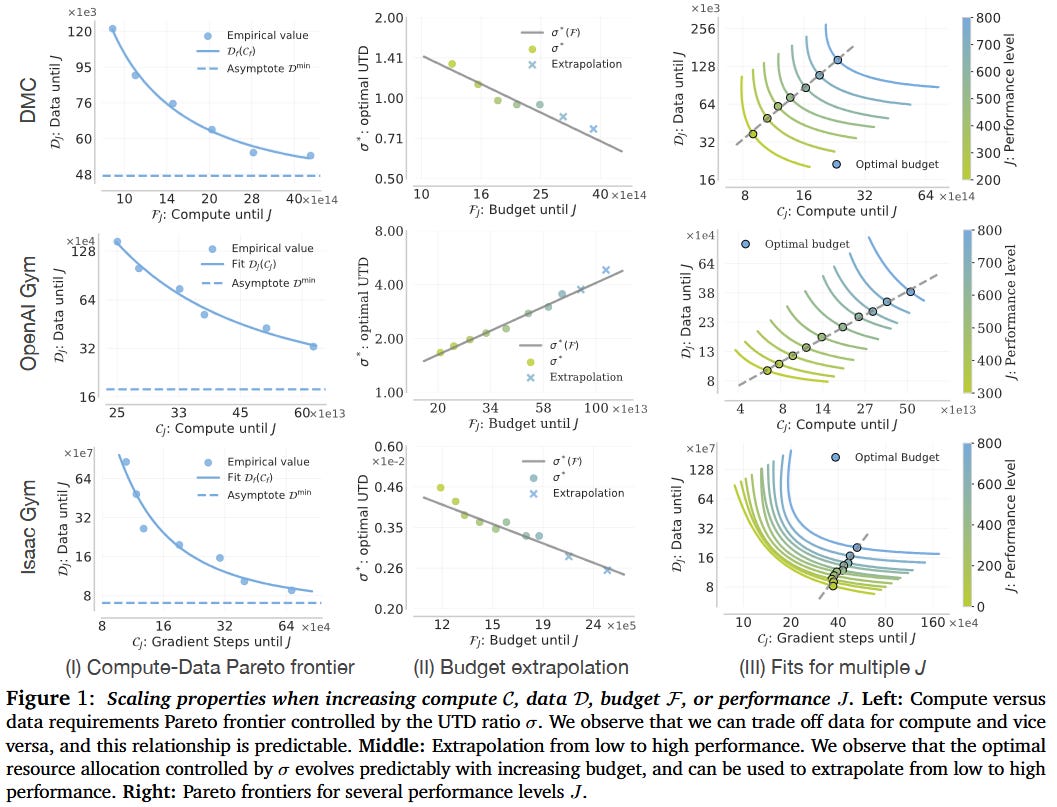
The researchers found that by carefully tuning these hyperparameters, they could establish predictable scaling laws for value-based RL. Specifically, they discovered that the amount of data and compute required to achieve a given level of performance follows a Pareto frontier, a curve that represents the optimal trade-off between data and compute. This means that, for a given performance level, there is a predictable relationship between the amount of data and the amount of compute needed, and this relationship can be estimated from small-scale experiments.
The Pareto Frontier: A Roadmap for Scaling
The concept of the Pareto frontier is central to the paper’s findings. In essence, the Pareto frontier represents the set of optimal trade-offs between data and compute. For a given level of performance, there is a minimum amount of data and compute required, and these requirements lie on a curve that can be predicted using the UTD ratio. By estimating this curve, researchers can determine how much data is needed if they have more compute, or how much compute is needed if they have more data.
This predictability could be another game-changer for RL research. Instead of running expensive large-scale experiments, researchers can now extrapolate from small-scale runs to predict how their algorithms will perform with more resources. This not only saves time and money but also allows for more efficient allocation of resources. For example, if a researcher has a limited compute budget, they can use the Pareto frontier to determine the optimal amount of data to collect to achieve their desired performance level.
The Role of Hyperparameters: Batch Size, Learning Rate, and UTD Ratio
The paper also delves into the intricate relationships between the key hyperparameters in value-based RL. The researchers found that the batch size and learning rate are inversely proportional to the UTD ratio. This means that as the UTD ratio increases (i.e., more updates are made per unit of data), the optimal batch size and learning rate decrease. This relationship is crucial for preventing overfitting and plasticity loss, two common issues in RL.
Overfitting occurs when the algorithm performs well on the training data but poorly on new data. In RL, this can happen because the data distribution changes as the policy improves, leading to a mismatch between the training data and the data generated by the new policy. By reducing the batch size, the algorithm sees each data point fewer times, which helps mitigate overfitting.
Plasticity loss, on the other hand, occurs when the algorithm becomes less capable of adapting to new data as training progresses. This is often caused by large learning rates, which can lead to large updates that make it difficult for the algorithm to fit new targets. By reducing the learning rate as the UTD ratio increases, the algorithm can maintain its plasticity and continue to learn effectively.
Empirical Validation: From Small-Scale to Large-Scale
The researchers validated their findings through extensive experiments on three different RL benchmarks: DeepMind Control Suite, OpenAI Gym, and IsaacGym. They tested three value-based algorithms—SAC, BRO, and PQL—and found that the scaling laws held across all three domains. This suggests that the predictability of value-based RL is not limited to a specific algorithm or environment but is a general property of these methods.
One of the most impressive aspects of the study is its ability to extrapolate from small-scale experiments to predict performance at much larger scales. For example, the researchers were able to predict the optimal hyperparameters and resource allocations for high-budget runs using only data from low-budget runs. This ability to extrapolate is crucial for practical applications, where running large-scale experiments is often infeasible.
Limitations and Future Directions
While the study shows a major step forward in understanding the scaling behavior of value-based RL, it also raises several important questions for future research. For example, the study focused on three key hyperparameters—batch size, learning rate, and UTD ratio—but there are many other factors that could influence the scaling behavior of RL algorithms. Future work could explore the role of other hyperparameters, such as model size, weight decay, and weight reset frequency, in determining the scalability of RL algorithms.
Additionally, the study focused on online RL, where the algorithm collects its own data during training. However, many real-world applications involve offline RL, where the algorithm learns from a fixed dataset. Understanding how scaling laws apply to offline RL is an important direction for future research.
Finally, while the study demonstrated predictable scaling across a range of environments and algorithms, it is still unclear how these findings will generalize to even larger models and more complex tasks. As RL continues to push the boundaries of what is possible in AI, it will be important to verify these scaling laws at even larger scales.
Conclusion: Predictable RL?
The paper "Value-Based Deep RL Scales Predictably" implies a major breakthrough in our understanding of how reinforcement learning algorithms scale with increasing data and compute. By uncovering the predictable relationships between key hyperparameters and resource requirements, the study provides a roadmap for efficient and effective scaling of value-based RL methods. This predictability not only saves time and resources but also opens up new possibilities for large-scale RL applications in areas ranging from robotics to game playing to autonomous driving.
Paper: Value-Based Deep RL Scales Predictably | https://arxiv.org/pdf/2502.04327